

Knowledge Base & Support
TOPICS
Optimise Registration
The Optimise Registration job allows you to tighten up and distribute error globally to obtain the highest quality registration possible with Vercator. This registration job requires that the data from jobs selected as input are already pre-registered either from an Auto Registration job, Manual Registration Job or before the data was imported to Vercator, e.g. from the scanner.

Job Creation
- From the Create a New Job menu select Optimise Registration.
- You will get a warning that the data must be pre-registered before running Optimise Registration, as the process can only make small adjustments.
- Select the jobs to be included on the left hand side with the checkboxes and choose ‘Add Selected’ or just press ‘Add All’ without selection, as appropriate. Then press ‘Next’.
Either imported data, auto registration, optimise registration or manual registration result can be used as input.
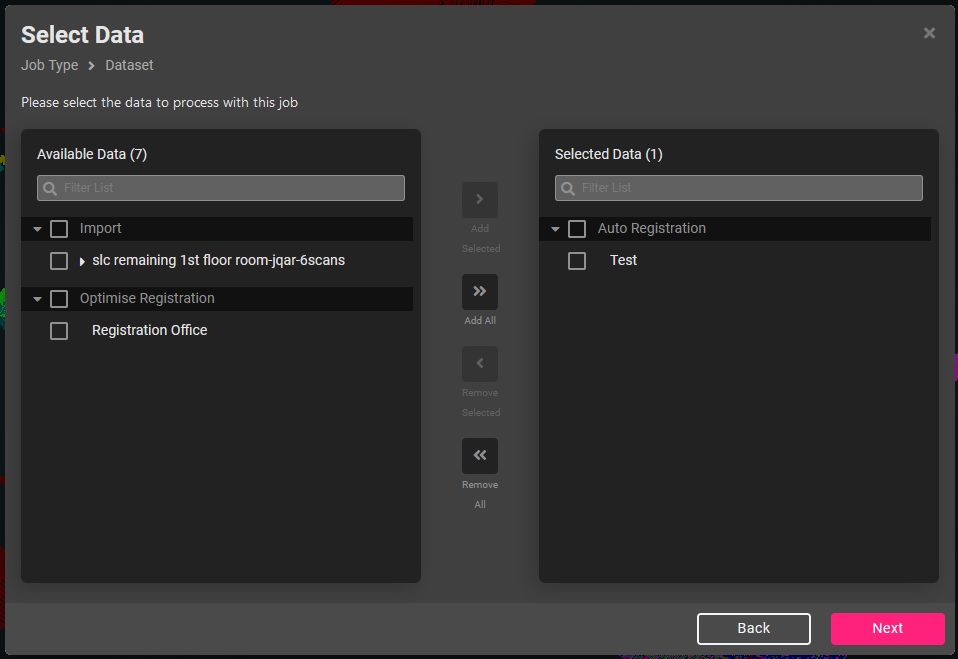

- After choosing data and pressing Next the user can choose to change settings from their defaults as required.
Settings
The settings for Optimise Registration are described below.
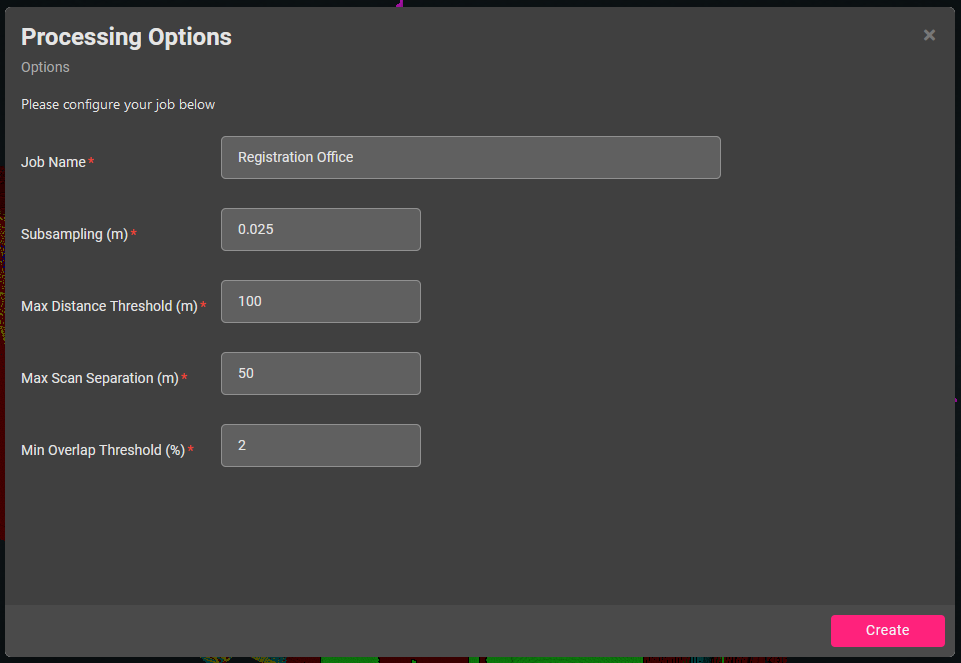
- Job Name
- Subsampling: the minimum distance between points; a smaller figure increases processing time. This evens out the spacing of points in the scans to avoid bias from the dense amount of points close to the scanner.
- Max Distance Threshold: the maximum point distance from the scanner to use in the registration. Longer range scans may require a larger value here to take into account more common features at range.
- Maximum Scan Separation: maximum distance between any two scan positions for them to be considered for further processing to each other in a cluster or bundle. If this value is too small the registration may be of lower quality as fewer scans are clustered together to refine the solution.
- Minimum Overlap Threshold: minimum overlap between scans to consider calculating fine registration group solution with. This setting can affect scans with long range points where a tiny fraction is overlapping a series of much denser scans clustered nearer to a specific scene. A larger percentage may be less precise at distance but computes faster, whereas a smaller percentage may be more precise at distance but more sensitive to noise and compute slower.
Optimise Registration Quality Report
Once the job has finished a report will be calculated for QA checking. You can view a full breakdown of the statistics of the Optimise Registration in this job report.
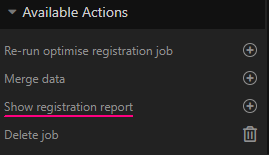
To access the report, choose Show registration report from the right sidebar Available Actions menu for the Optimise Registration job.
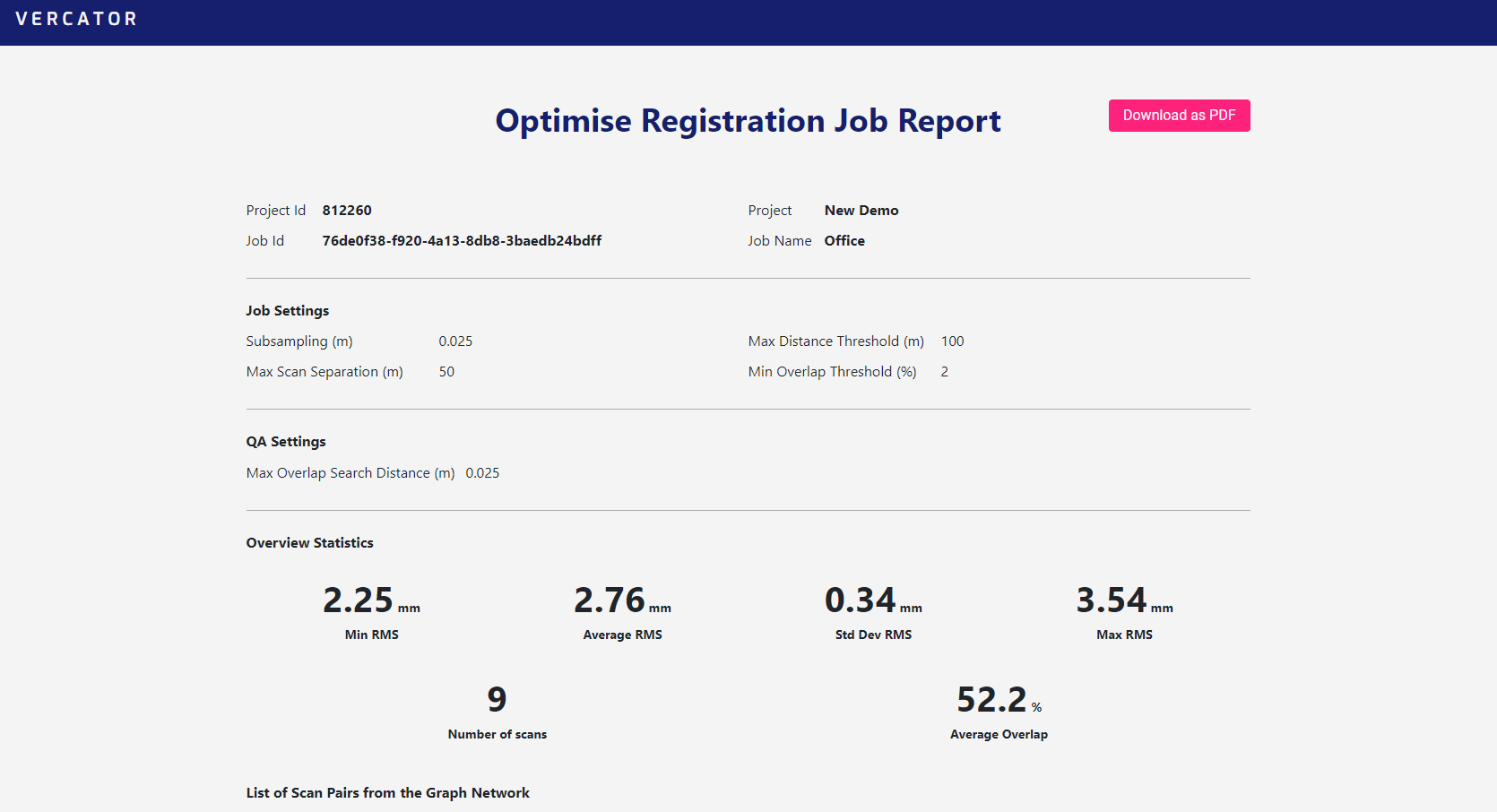
This will open the report in a new window. This report can be downloaded as a pdf, you can view a sample report here.
The report is broken down into some top level details such as overall average accuracy (RMS error) and overlap. Then a list of the scan pairs, their individual errors and overlap statistics, used for traceability and identifying problems.
Export
The result can be exported unstructured by first running a merge or, if the data is supported, it can be exported as structured data as described here.